6億6,600万人以上のアクティブ・ユーザーを有する。 ツイッター、または新ブランドのXTwitterは最も人気のあるソーシャルメディア・プラットフォームの一つであり、企業、研究者、個人にとって貴重な情報源である。しかし、膨大なTwitterデータの中から手作業でデータを抽出し、フィルタリングすることは、圧倒的で非機能的です。

Twitterのスクレイピングは、ソフトウェアやスクリプトを使用してプラットフォームからデータを収集します。 このデータを分析することで、トレンドのトピックやハッシュタグ、会話、プラットフォーム上で起きているインタラクション、ユーザーの行動に関する貴重な洞察を得ることができる。
収集された情報は、センチメント分析、市場調査、ソーシャルメディアモニタリングなど、様々な目的のために綿密に分析することができる。この記事では、様々な側面から こすり スクリプトからノーコードソフトウェアまで、既存の方法を使ったTwitterデータ、関連コスト、合法性と倫理的条件。
目次
ツイッターから抽出できるデータの種類は?
様々なタイプのTwitterデータを抽出することができます。ここでは、Twitterスクレイピングのための3つの主要なデータタイプを紹介します:
- ツイート プロフィールに基づいてフィルタリングされたツイートから、「いいね!」、返信、リツイート、指定したURLなど、特定のデータを取得することができます。
- ユーザーのプロフィール ユーザーの経歴、プロフィールの説明、ツイート数、リツイート数、フォロワー数/フォロー数、プロフィール画像など、公開されているユーザープロフィールのあらゆるものが収集可能です。
- キーワード/ハッシュタグ 特定のキーワードやハッシュタグ、またはそれらの組み合わせを含むツイートを収集することができます。いいね!の数で絞り込んだり、特定の日時で検索することも可能です。
合法性と倫理的な利用規約
データスクレイピングの世界に飛び込む際には、法的および倫理的な境界線を理解することが不可欠である。
によると ツイッター規約 (デベロッパー規約およびポリシー)、明示的な許可なくデータをスクレイピングすることは禁止されており、Twitterのポリシーによって宣言されています:「Twitterの事前の同意なしに本サービスをスクレイピングすることは明示的に禁止されています。
これらの目的でTwitter APIを悪用した場合は、アクセスの停止や終了を含む強制措置の対象となります。
Twitterスクレイピングの一般的なガイド
Twitterスクレイピングについて簡単に紹介した後は、いよいよTwitterデータを使ったスクレイピングのプロセスを探ろう。そこで、Twitterスクレイピングの簡単で包括的なガイドをまとめました。以下の手順に従ってください:
- まず、適切なスクレイピング・ツールを用意する必要がある。たくさんの選択肢から選ぶことができる。自分の予算と好みに合ったものを選びましょう。
- スクレイピングツールをダウンロードし、システムにインストールする。
- お使いのデバイスに十分なストレージ容量があり、信頼できるインターネット接続があることをご確認ください。
- インストール後、Twitterアカウントの詳細を使ってログインします。
- Twitterからデータをスクレイピングするためのパラメータを調整することは、キーワード、ハッシュタグ、日時、場所、URLなどに基づいてデータを抽出することを可能にする重要なステップです。
- スクレイパーツールを実行すると、大量のデータが残ります。そのデータをさまざまなファイル形式(xlsx、CSV、JSONなど)にエクスポートできます。
- 最後のステップでは、エクスポートしたデータを分析して、関心のあるトピックに関する洞察を得る必要があります。
Twitterスクレイピングツールと方法
インターネット上で利用可能ないくつかのスクレイピングツールをレビューした。 ツイッタースクレーパー サードパーティのサービスやオープンソースのPythonライブラリまで、以下にリストアップした。
4.1.APIベースのTwitterスクレイパー
最初に取り上げるのは、APIベースのTwitterスクレイパーで、Twitter API V2、Apify、Brightdata、Scrapingdogなどがある。
4.1.1. Twitter API V2
Twitter API v2はTwitterのAPIの最新バージョンで、ソーシャルインタラクションを使ったアプリを開発する開発者や、特定の目的のためにデータを収集する研究者や個人にとって、公式かつ最も一般的に使用されているAPIの1つです。新しいAPIを使用することで、ソーシャルネットワーク上のライブの会話を簡単にモニタリングし、分析することができます。
最近、ツイッターは、エンドポイント、ツイート投稿のペイロードオプション、会話識別子セット、アノテーションなどの新機能を追加した。これらの変更は非常に印象的だ。しかし、新しい料金体系は、開発者やサードパーティアプリにとって深刻な懸念材料となっている。新しい料金体系によって、サービスへのアクセスは劇的に減少し、価格は大幅に上昇した。
Twitter/X API v2の料金プランには3つのレベルがある:無料、ベーシック、エンタープライズ。
- 無料ティアでは、デベロッパーは以下の投稿が可能です。 月間1500ツイート書き込み専用で、Twitter APIのテスト用に設計されています。
- 基本料金 月額$100、月間3,000ツイートまで投稿可能。 ユーザーレベルで ツイート数50,000(閲覧制限10,000) アプリレベルで。
- エンタープライズ・タイヤには、ビジネス向けに設計されたより高度な機能が含まれています。しかし、エンタープライズ・プランでは、開発者/企業に対して、次のような法外な価格が請求されます。 月に約42000$.
4.1.2. アピファイ
ApifyのTwitter Scraperを通して、ハッシュタグ、スレッド、返信、画像など、公開されているTwitterデータから情報を抽出することができます。最近のツイッターの変更により、このプラットフォームでのツイートの閲覧やスクレイピングに新たな制限が設けられました。このスクレイパーは最新のツイートをスクレイピングすることはできないが、最も「いいね!」されたツイートを取得することはできる。抽出されたデータはHTML、JSON、Excel、CSV形式でアクセスできる。
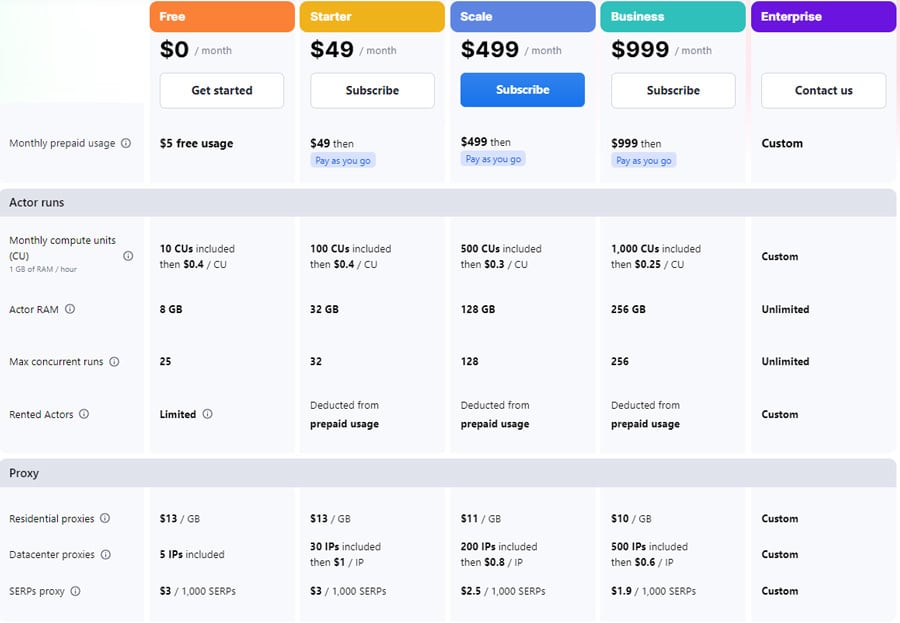
以下の図は、アピファイによる月額サービス費用を示しています。また、年間プランには10%の割引があります。詳しくは アピファイ価格.
4.1.3. ブライト・データ
Bright Dataは、プロキシサーバー、API、ノーコードソリューションなどのウェブスクレイピングツールを提供するデータ収集プラットフォームです。Bright DataのWeb Scraperは、画像、動画、ツイート、ハッシュタグなど、公開されているTwitterプロフィールからデータを抽出する機能をユーザーに提供します。
月額500$(151000ページロード)からご利用いただけます。.Bright Data Twitter scraper データコレクターは、すべてのウェブサービスと互換性があり、データをエクセル形式で出力します。また、7日間のトライアルを提供しており、500ドルを支払う前にプラットフォームをテストすることができます。
4.1.4. スクラップドッグ
Scrapingdogは、Twitterを含むあらゆるウェブサイトのスクレイピングを支援するウェブスクレイピングAPIです。ツイートIDを使ってツイートをスクレイピングしたり、公開ページをスクレイピングしてフォロワー数、フォロワー数、ウェブサイトリンクなどの詳細を抽出することができる。
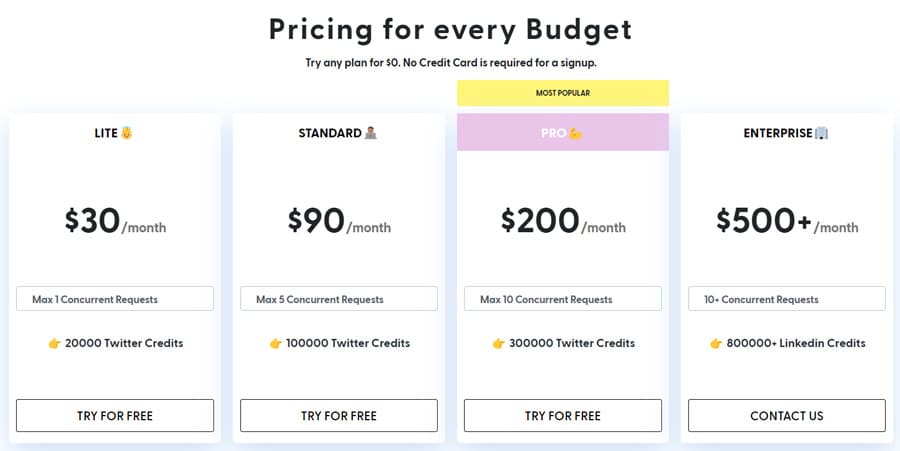
Twitterのスクレイピングには1ページあたり0.0009$かかります。 標準プランでは、他のトップTwitterスクレイパーと比較して、価格以上の最高の価値の一つです。Scrapingdogは無料トライアルも提供している。Scrapingdogを使ったデータスクレイピング方法の詳細については、以下をご覧ください。 Twitter Scraping API ドキュメント.
4.2.TwitterスクレイピングのためのPythonライブラリとパッケージ
Twitter APIとApifyのようなアプリに慣れてきたところで、TwitterスクレイピングのためのPythonライブラリとパッケージを見てみましょう。
4.2.1. トゥイーピー
TweepyはオープンソースのPythonパッケージで、開発者はTwitterのエンドポイントにスムーズかつ透過的にアクセスできる。しかし、TwitterがX/Twitter APIに送信するリクエスト数に制限を課していることに注意する必要があります。 15分ごとに900件のリクエストが可能.このセクションでは、Tweepyの機能と簡単な例を紹介します。
まず、Python IDE上で "pip install Tweepy "コマンドを使ってTweepyパッケージをインストールし、Tweepyもインポートします。クライアント・アプリケーションをTwitterに登録するのが次のステップです。新しいアプリケーションを作成してください。登録が完了すると、ベアラートークンが発行されます。
|
1 2 |
ピップ install トゥイーピー インポート トゥイーピー |
次に、Twitter APIから取得したコンシューマー・ベアラ・トークンを渡すための "Client "インスタンスを作成しなければならない。
クエリー変数には、フィールド、言及、ハッシュタグを指定した。
|
1 2 3 |
クライアント = トゥイーピー.クライアント(ベアラートークン='bearer_token') クエリー = 'query @mentions #hashtags' |
過去7日間のツイートを検索するには、Tweepyで利用可能なsearch_recent_tweets機能を使用できます。探しているデータを指定するには、検索クエリを渡す必要があります。
|
1 2 |
最近のツイート = クライアント.検索_最近のツイート(クエリー=クエリー, ツイートフィールド=#91;'tweet_field_1', 'ツイート_フィールド_2'], 最大結果=100) |
学術研究プロダクトトラックへのアクセス権をお持ちの方は、7日以上前のツイートを取得することができます。一般公開されているツイートの完全なアーカイブから。
|
1 2 |
ツイート = クライアント.検索_すべてのツイート(クエリー=クエリー, ツイートフィールド=#91;'tweet_field_1', 'ツイート_フィールド_2'], 最大結果=100) |
以下のコードで結果をエクスポートできる。
|
1 2 3 4 5 |
にとって ツイート で ツイート.データ: プリント(ツイート.テキスト) もし レン(ツイート.コンテキスト注釈) > 0: プリント(ツイート.コンテキスト注釈) |
Tweepyには、より複雑で特殊なケースでさまざまなタスクを実行できる関数もたくさんある。
4.2.2. スネクレープ
APIに頼らずにツイッターから情報を取得するもう一つの方法は、Snscrapeを使うことだ。Snscrapeを使えば、ユーザーのプロフィール、ツイートの内容、ソースなどの基本的な情報を取得することができる。Tweepyとは異なり、スクレイプできるツイートの数やツイートの日付に制限はなく、古いTwitterデータも抽出できる。SnscrapeはTwitter APIに接続していないため、Tweepyのような機能はありません。詳しくは スネクレープ.
このセクションでは、PythonのSnscrapeを使ってTwitterからデータをスクレイピングする基本的な例も紹介する。
まず、Snscrapeをインストールしてください。Python 3.8以上がインストールされている必要があります。
|
1 2 |
ピップ install スネクレープ |
次のステップでは、以下のライブラリをインストールする。
|
1 2 3 |
インポート スネクレープ.モジュール.ツイッター として ツイッター インポート パンダ として ピーディー |
TwitterSearchScraper(query).get_items "関数を使ってクエリー(ここでは "query")を送信し、Twitterの検索バーの結果と同じように検索結果を取得する。
|
1 2 3 4 5 6 |
クエリー = 「クエリー にとって ツイート で ツイッター.TwitterSearchScraper(クエリー).アイテム(): プリント(バーズ(ツイート)) 休憩 |
Twitterからデータをスクレイピングするために使用できるメソッドは他にもある:TwitterSearchScraper, TwitterUserScraper, TwitterProfileScraper, TwitterHashtagScraper, TwitterTweetScraperMode, TwitterTweetScraper, TwitterListPostsScraper, TwitterTrendsScraper.
まとめ
ツイッターは、ウェブ全体の社会学的情報源として価値がある。Twitterからスクレイピングされた情報を活用することで、売上を伸ばしたり、マーケティング戦略を改善したりするための計画を立てることができます。この記事では、ビジネスやリサーチに役立つデータを抽出するためのTwitterスクレイピングの様々な側面と方法について、詳しくご紹介しました。
まとめると、Twitter API v2に課された新たな制限と高いコストにより、最適なスクレーパーを選択することは難しいだろう。Twitter APIのより高度な機能、またはTwitter APIに直接接続されているサードパーティのアプリやPythonライブラリ(Tweepy)の恩恵を受けることができる。しかし、リクエストできる数は厳しく制限されている。一方、一般に公開されているデータをスクレイピングしようとする場合、基本的な機能でニーズを満たすのであれば、Snscrape Pythonライブラリのようなオプションは素晴らしい選択肢となるだろう。
免責事項: 本資料は、情報提供のみを目的として作成されたものです。いかなる活動(違法行為を含む)、製品、サービスを推奨するものではありません。当社のサービスを利用する場合、またはここに記載されている情報に依拠する場合は、知的財産権法を含む適用法を遵守する責任を負うものとします。当社は、法律で明示的に義務付けられている場合を除き、いかなる方法であれ、当社のサービスまたはここに含まれる情報の使用から生じる損害について一切の責任を負いません。
0コメント